“安全智能”的背后,Ilya 究竟看到了什么?
发布日期:2024-09-19 21:16
来源类型:每日甘肃 | 作者:Kurylo
| 【494949澳门今晚开什么】 【2024新澳免费资料】 【新澳历史开奖走势图】 | 【澳门金牛版正版资料大全免费】 【新澳开奖记录今天结果】 【2024年新澳门王中王资料】 【管家婆最准一肖一码】 【新澳彩开奖结果查询】 【澳门特马开奖开奖结果历史记录查询】 【4949澳门免费资料大全特色】 【2024今晚澳门特马开什么号】 【新奥六资料新澳】 【2O24澳彩管家婆资料传真】
文|飞哥说AI,作者| 李维、高佳
文|飞哥说AI,作者| 李维、高佳
当Ilya Sutskever离开 OpenAI重归大众视野,带着他名为SSI(Safe Superintelligence Inc.)的新公司。
这一举动惊讶之余又在意料之中——Ilya 直接跳过 AGI ,直指SSI (Safe Superintelligence)。
他笃定表示:“超级智能已近在咫尺,建立安全的超级智能(SSI)是我们这个时代最重要的技术问题。
”这位深度学习和AI 领域的传奇,前 OpenAI 的真正灵魂人物,Ilya 在那场戏剧性的内变事件中,始终处于风暴中心,也直指杠杆问题——有效加速还是超级对齐?
这场关乎AI价值观和路线之争的底层,Ilya 为何对“超级对齐”如此坚定?
以至风暴平息后,外界一直在猜测:Ilya 究竟看见了什么,促使他必须联手董事会作出驱逐CEO Sam Altman 的决定。此后的 Ilya 一直隐身,直到不久前挥一挥衣袖离开 OpenAI,他带领的超级对齐团队也因此解散。Ilya 转身创立新公司。
“安全智能”的背后,他究竟看到了什么?
早在 2023 年 10 月 3 日,Ilya 曾在伯克利大学做过一次演讲,题为《一个无监督学习的理论》(A Theory of Unsupervised Learning)。由于内容艰涩,知晓者寥寥,而它却是人工智能史上最重要的时刻之一,注定将载入史册。
这次演讲堪称一位深度学习领域顶尖专家对自己开创、如今名冠天下的GPT模型的理论反思和总结。
Ilya 在演讲中揭示了大模型的核心原理,并生动描述了他在独立领悟无监督序列学习机制时的痴迷,兴奋之情溢于言表。虽然理论晦涩,听懂他的人也极为有限,但演讲本身却精彩绝伦、振聋发聩。
直到前不久,超级对齐团队的前成员 Leopold Aschenbrenner 发表了一篇长达165页的文章《Situation Awareness》,初步揭示了 OpenAI 内部目睹 GPT 模型指数级进化时的震撼和隐忧。
这多少部分回答了 Ilya 看到了什么的问题,而 Ilya 本人一直缄默,直至今天官宣出山。
回顾他在伯克利的自白式演讲,似乎可以一窥他面对潜在超级智能时的「顿悟」时刻,回答他对安全智能的「初心」。那是 Ilya 一次罕见的深度分享,试图为世人传真经。
世人听见了吗?
机器学习:监督学习与无监督学习
为了兼顾不同数学基础的读者,本文力图主要用通俗易懂的语言深入浅出解读 Ilya 的这一重要的技术演讲。纯粹技术性的解说,非技术人员可以选择略过,并不影响对于这篇演说的主旨的理解。
精读之前,我们复习一下机器学习的基本概念。
大家都知道,机器学习就像让计算机当学生,人类当老师,通过给计算机大量的“练习题”和“答案”,让它慢慢学会解题的能力。这就是监督学习(supervised learning)。但是,计算机真的能从练习题中学到本事,而不是死记硬背吗? Ilya 告诉我们,这是有理论保证的。
想象一下,眼前有一大堆题海,每道题都配有标准答案。这就是模型的训练数据。模型训练就是勤奋刷题,终于把这些题几乎都做对了,这意味着训练误差很低。但是题海再大,总有刷完的一天。
当新题摆在面前,还能答对吗?新题就是测试数据,相当于考试,能否答对,取决于模型的测试误差。
数学告诉我们,只要题海足够大,远远超过模型的规模,那么模型在训练题上的出色表现(低训练误差),就能确保在考场上的发挥(低测试误差)。换句话说,题海刷得好,考场差不了!这就是监督学习的数学保证。
当然,题海再大,如果只是死记硬背,不去归纳总结,你的脑容量再大、“记忆力”再强,也只是一个填鸭式的学霸,缺乏真正的学习应变的能力(叫做“泛化”能力)。
只有当你的大脑袋里面的“小聪明”不要太高(聪明反被聪明误),才会被迫去总结规律,提炼精华(业内叫“压缩”),从题海中学到真本事。
这就是为什么模型规模不能太大,不能给模型太多的投机取巧的空间。
总之, Ilya 想说的是,大数据+低训练误差,就是监督学习的制胜法宝,有数学证明为保证。这一点,从理论到实践都已得到证实。
自从12年前深度学习革命以来,无数成功案例告诉我们,只要训练数据足够充足,神经网络就是“学霸”,从识别猫狗到机器翻译,都难不倒它。
但无监督学习呢?没有标准答案的题海,计算机还能学到智能吗?听起来有点悬,但 Ilya 接下来就要讲,他是如何试图为无监督学习也寻找到坚实的数学基础的。
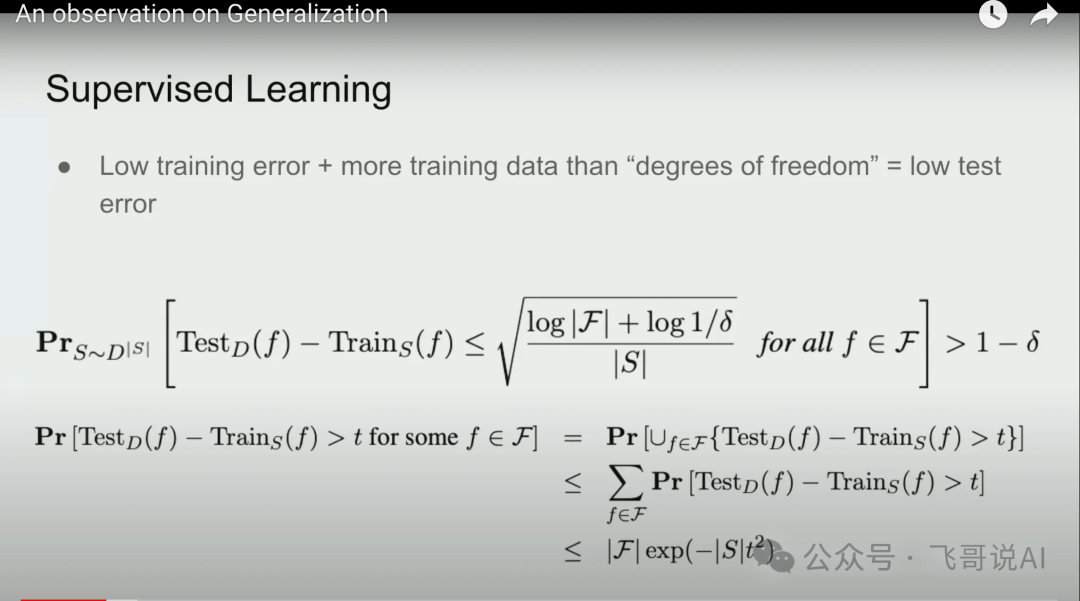
这是 Ilya 讲演的第一帧slide,从监督学习讲起,给出了理论上的保证。
所谓理论就是那个统计学习理论中著名的 Hoeffding 不等式,其主要含义是:当训练误差足够低,且训练样本数远大于“模型自由度”(可以理解为模型的规模)时,测试误差也能保证足够低,这就是监督学习能够起作用的理论基础。
具体说,就是模型规模一定要小于数据规模,否则,它根本就不用做真正的“压缩”或抽象,不去找规律,它就全部死记硬背了。我们知道死记硬背的模型,没有泛化能力。
它在训练集上死记硬背,考了高分,到了盲测的测试集上就抓瞎了,模型的质量就得不到保证。所以公式里面,模型复杂度(模型大小)是个关键变量。
具体的解读如下表所示,数学基础不足的读者可以跳过这些公式理解的细节,并不影响对于主旨的理解。

总之,本页 slide 表达的核心观点是:低训练误差+大训练集,就能确保模型的泛化能力,这就是监督学习背后的理论保证。
这个其实我们早已知道,第一,宏观上和理论上,“万能近似定理”(Universal Approaximation Theorem)早已论证了深层神经网络可以逼近任意函数。
第二,当代 AI 历史上,12年前的深度学习革命就开始证明,只要有足够带标数据,神经网络就可以让“老母鸡变鸭”,或做任何其他变换。

Ilya 接着说,不像监督学习有明确的数学保证,无监督学习似乎缺乏类似的理论支撑。但是,他发现了一种叫做“分布匹配”(distribution matching)的范式,似乎能让无监督学习也获得数学保障。这话一出,大家都来了兴趣,洗耳恭听。
你可能会说,无监督学习不就是在学习数据的内在特征吗?比如,从一堆没有标签的猫狗图片中,自动归纳出猫和狗的共同特征。这对以后分类猫狗确实有帮助。
但如果这堆图片是完全随机的涂鸦,乱成一团,那无监督学习还能学到什么吗?另外,就算学到了猫长胡须狗长尾巴,这些知识对别的任务,比如识别交通标志,有什么用呢?
Ilya 说,问题的关键在于我们要透过现象看本质。比如GPT这样的语言模型,表面上是在学习预测下一个词(next token prediction)。
实质上,它在匹配语言的分布,学习语言的隐含规律。比如,在“我爱吃苹果”这句话里,“我爱吃”后面更可能出现“苹果”,而不是“砖头”,这反映了语言的内在知识。
这种分布匹配,是一种特殊的模式规律的匹配。不同的是,它匹配的不是具体的字符串或词串(token sequence),而是词与词之间的关系,也就是语言的规律性,类似于语义结构。 Ilya 认为,这种分布匹配,才是无监督学习获得智能的本质。不管是文本、图像还是语音,它们都有内在的分布规律性,而无监督学习就是要发现、匹配和对齐这些分布规律。
所以,图片不能太随机,数据集不能都是涂鸦,得有一定的规律性,无监督学习才能抓住它们的隐藏共性。至于学到的知识对别的任务有没有用,那要看这些任务的数据分布是不是相似。如果都是自然图像,那从猫狗身上学到的特征,多少还能迁移到其他动物身上。但如果是完全不同的领域,比如医学影像,那可能就没啥参考价值了。
总之, Ilya 给了我们一个新的视角:无监督学习的本质是分布匹配,是一种规律性的模式匹配。这个视角,似乎为无监督学习的有效性提供了一种解释。接下来, Ilya 将进一步解释,分布匹配是如何给无监督学习提供理论保证的。
分布匹配:无监督学习的新思路
大家都知道,机器翻译曾是监督学习的天下。为什么?因为我们有历史积累的海量人工翻译数据啊。就像学生有课本和习题册,英语在左边,汉语在右边,监督学习就吃这一套。
但是,如果老师突然不给双语对齐数据了,只给你一些英语书和另一些不相干的汉语书,让你自己琢磨怎么对齐学习自动翻译,你该怎么办?
这就是无监督学习要解决的问题。 Ilya 说,无监督学习也能搞定各种语言的机器翻译(当然能,现在我们都在大模型模型中见识了,大模型把机器翻译早已搞得妥妥的了,我们不再需要专门的翻译软件了),甚至任何从输入到输出的转换任务。这是什么原理呢?
原来, Ilya 发现了一个新思路,就是前面提过的分布匹配。啥意思?就是说,如果英语书库和汉语书库足够大,包含了各种句型和语法,那它们的语言规律性就会显现,就可以无监督学到。比如,英语里出现"I/me/my"的上下文分布,和汉语里出现"我"的分布应该有某种对应的规律性;英语里形容词放在名词附近,并且语义相谐,汉语里应该也差不多,等等。这就为潜在的语言对齐提供了基本条件。
Ilya 指出,只要两种语言原生数据足够丰富,一种语言的输入作为条件就能几乎唯一地确定另一种语言的翻译等价物。而且,这个原理不仅适用于机器翻译,还适用于语音识别、图像转换等各种AI任务。
Ilya 在2015年就独立发现了这个思路,他被它背后的数学原理迷住了。那是啥原理?就是所谓“压缩”理论。如果我们能找到一个方法,既能最大限度地压缩英语数据,又能最大限度地压缩汉语数据,那这个方法就能抓住两种语言的共同规律,而这些规律就是翻译的基础。
所以 Ilya 提出,无监督学习其实就是在寻找最优的数据压缩方法。这个视角不仅很酷,还能让无监督学习的有效性有了数学上的解释。虽然现实中的任务没有那么理想化,但这个原理让无监督学习有了坚实的理论基础,可以和监督学习一样有说服力。
接下来, Ilya 还会进一步讲解背后的数学原理。虽然有点抽象,但他保证干货满满。我们拭目以待,看他如何用压缩的魔法来解释无监督学习的奥秘。
下面是技术性的细节解读,主旨不变,读者可以选择跳过去。
什么是基于分布匹配的无监督学习呢?
给定两个没有直接对齐的数据集X和Y (比如英语和法语的语料),我们要找到一个函数f,使得f(X)的分布与Y的分布相似。在机器翻译、语音识别等转换任务中,如果X和Y的维度足够高,X这个条件能提供很强的约束,几乎可以唯一地决定f(X)。后面会证明,这种无监督学习方法对任意端到端的任务Y=f(X)都有其理论保证,类似于监督学习的数学保证。
Ilya 在2015年独立发现了这一思路,并对其数学原理(Kolmogorov复杂性,简称K氏复杂性)产生了浓厚兴趣。但他也指出,现实中的机器学习任务与这种理想化的分布式匹配还是有差距的。但这不影响他讲原理。
接下来,Ilya提出了他主要想说的观点:把无监督学习看作是一个数据压缩问题,可以让我们从数学上理解无监督学习为什么有效,在任务执行上使之与监督学习处于同等地位。
他指出,压缩和预测之间有一一对应关系,每个压缩算法都对应一个预测模型,反之亦然。他说,尽管这一点可能不那么直观,但已经是一个广为人知的结论了。可以这样理解,压缩的逆操作是解压缩,解压缩的同义词是预测。所以, Ilya 认为都是一回事。 机器学习中的过程与逆过程是推理阶段的指向不同而已,从模型角度看是一回事。这引出了后面的他一再声称是“纯干货”的大模型无监督学习的理论,即K氏复杂性。
这张 slide 的表达方式非常奇特,他似乎觉得需要引入一个“遗憾指数”来表达他对于自学习搞定所有任务的信心:没有遗憾。
Ilya 提出了一个从压缩视角来形式化无监督学习的思路。考虑一个机器学习算法A,它试图去压缩数据集Y,同时可以利用另一个无标注数据集X。我们的目标是让A尽可能好地压缩Y。那么怎么衡量算法A的性能呢? Ilya 引入了“遗憾(regret)”这个概念。
如果A的“遗憾”很低,就意味着:我们已经充分利用了无标注数据X中的所有信息,来帮助压缩Y。换句话说,没有人能比我们做得更好了。如果X中存在任何对Y有用的模式,我们已经尽力去挖掘和利用了。
据称这就提供了一个评估无监督学习算法的角度:好的算法应该能最小化这种“遗憾”,充分挖掘无标注数据的价值,让我们晚上“睡得安稳”,不必担心还有进一步提升的空间没有利用。以压缩而论,就是要原则上能够榨干海绵中的最后一滴水。
当然,无标注数据X的压缩实际上对预测Y有多大帮助,可能有巨大差异。X可能含有破解Y的关键(例如语言之间的机器翻译,这是因为语言与语言的深层语义是同构的,具有天然的可对齐特性),但也可能X对于预测Y没什么用处。无论如何,一个“低遗憾”的无监督学习算法,应能根据X的实际效用,尽力压缩X来预测Y。
总的来说, Ilya 为刻画和理解无监督学习提供了一个他自己的(有点古怪的)视角,让我们聚焦于从无标注数据中学习有用信息这一核心问题上。
下面要谈计算理论了,他先给了个警告,说这个理论有点晦涩。
Ilya 讨论了Kolmogorov复杂度作为“终极压缩器”的性质,以及它与无监督学习的关联。
关于压缩的理论,想象你是一个特工,你的任务是把一份机密文件传递给你的同伴。但是这份文件太大了,你没法直接携带。所以你决定对文件进行“压缩”,找到一种最简洁的方式来表达文件的内容。
这就引出了K氏复杂度的概念。在特工的世界里,一份文件的 K氏复杂度就是能够完整描述这份文件的最短指令。你可以把这个最短指令想象成一套“暗号”,只要你的同伴知道这套暗号,他就能完全还原出文件。
现在,假设你有两份文件要传递,一份是机密情报(数据集X),另一份是行动计划(数据集Y)。为了安全起见,你不能直接把行动计划写出来。但是,你觉得机密情报里可能隐藏着制定行动计划的线索。所以,你希望找到一种方法能最大限度地解码机密情报,来指导行动计划的制定。
这就是无监督学习要解决的问题。在 Ilya 看来,一个好的无监督学习算法,应该能找到数据的最简洁表示(即 K氏复杂度),同时又能最大限度地利用这种表示来完成下游任务。例如,下游任务是解函数 y=F(x),那么算法就是要找到x与y的K氏复杂度,借此找到输入x到输出y的映射关系F。
然而,从数学上讲,真正的K氏复杂度是不可计算的,就像我们没法为每一份文件都找到最完美的暗号。但 Ilya 认为,我们可以训练一个大型神经网络(如GPT)来近似这个过程。因为理论上,神经网络可以拟合任何函数,包括“生成文件的最短指令”这个函数。通过不断调整网络的参数,我们就可以一步步逼近最优的压缩方案。
为了证明K氏复杂度是最佳的压缩器, Ilya 给出了一个数学论证。用特工的比喻来说,大意就是,任何一套暗号的编码,加上解码指令的长度以及制定和理解这套暗号所需的额外信息,一定多于最简洁的“完美暗号”,即K氏复杂度。
所以,K氏复杂度代表了压缩的理论极限,任何实际的压缩算法都不可能超越它。虽然这个极限不可达,但它为我们评判无监督学习算法提供了一个基准。 Ilya 认为,GPT 等大型语言模型之所以有效,正是因为它们能通过梯度下降等优化算法,不断逼近这个基准,学习到数据的高度压缩表示,并运用于下游任务。这就是K氏复杂度和无监督学习的联系。虽然有点抽象,但核心思想是清晰的:压缩是无监督学习的本质,而追求最简洁的压缩,就是追求最优的无监督学习。
下面是上述内容的技术性解说,主旨不变,不关心技术细节的读者可以选择跳过去到下一帧slide的解读。
首先,一个对象的K氏复杂度被定义为能够输出该对象的最短程序的长度。直观上,这个最短程序就是对象的最优压缩。K氏复杂度给出了压缩问题的一个通用下界。
假设我们有一个数据对象X(可以是一个字符串、一张图片等),如何对X进行压缩呢?一种直观的想法是找到一个程序P,使得P的输出就是X。如果P的长度比X短,那么P就可以看作X的一个压缩。K氏复杂度的思想是,P包含了产生X所需的全部信息,但又不包含任何多余信息,是一种无冗余的表示。这就是“无损压缩”的概念。
现在回到无监督学习。假设我们有未标注数据集X和下游任务数据集Y。如果要最大限度利用X去帮助预测Y,就希望找到一个算法,能最优地压缩X,同时还能利用从X中学到的知识去帮助预测Y。
就是说,算法应该能计算X和Y的K氏复杂度,得到它们的最短程序表示,并利用X的表示去优化Y的表示。如果算法能做到这一点,就意味着它把X中一切有助于Y的信息都提取出来用到了。 Ilya 把这种性质叫做“无遗憾”,因为我们没有浪费X的任何有用部分。
问题在于,从数学上可以证明,K氏复杂度是不可计算的,也就是说不存在一个算法能够对任意输入X算出最短程序P。所以完全理想的“无遗憾”的无监督学习在计算机里是无法实现的。但 Ilya 认为,我们训练的大型神经网络GPT,在某种意义上可以看作是K氏复杂度的一个近似。因为神经网络是一个通用的函数拟合器,理论上能逼近任何函数(根据万能近似定理 UAT),包括"最短程序"。而SGD(随机梯度下降)让我们能够高效地适配网络权重,去逼近最短程序。所以 Ilya 觉得,无监督深度学习能work,背后的奥秘就在于它在找K氏复杂度的一个可计算的替代物。
具体看 slide, Ilya 在这里引入了一个不等式,刻画了理论上的K氏复杂度与一般压缩算法之间的关系: 任何数据的K氏复杂度一定是最短的程序,即最优的压缩。

这个公式的证明基于一个称为“模拟论证”(The Simulation Argument) 的反证法思想实验。

这个矛盾的关键在于,我们在构造程序 P 时,忽略了压缩器 C 本身的复杂度 K(C)。一旦我们考虑了这个复杂度,就会发现 P 的长度不可能短于 K(X),因为 K(C) 本身就不可能短于 K(X)。
这个证明实际上揭示了信息本身的一个基本性质:存在一个理论上的压缩极限,这个极限是由信息的内在复杂性决定的,而不是由我们的压缩技术决定的。
证明的价值在于它将 K(X) 从一个抽象的数学定义转化为了一个有实际意义的理论极限。它告诉我们,不管我们如何改进压缩算法,都存在一个理论上无法逾越的界限。虽然 K氏复杂度不可计算,但它为我们评估无监督学习模型提供了一个理论基准。
然而,就压缩而言,K氏复杂度最优,不等于 GPT最优。但按照 Ilya 的说法,他们“发现”GPT可能是K氏复杂度的最好逼近。GPT通过无监督序列学习做到了在AI各任务上的碾压效果,支持了这个发现。
Ilya 的终极理论:从条件建模到联合建模
这是 Ilya 演讲的最后一帧 slide,也是理论最精彩的奥秘,值得好好梳理和咀嚼。
无监督学习的目标通常被定义为“学习数据的内在结构”。 Ilya 提出用数据压缩的角度来理解无监督学习:一个好的无监督学习算法,应该能最大限度地压缩数据,最简洁地表示数据的内容。这就引出了K氏复杂度的概念。
一个数据对象的 K氏复杂度,就是能够完整描述这个对象的最短计算机程序的长度。可以想象,这个最短程序就像一个“压缩包”,里面包含了重构原始数据所需的全部信息。从这个角度看,无监督学习的目标就是寻找数据的最优压缩表示,也就是 K氏复杂度。
但在实践中,我们往往需要处理多个相关的数据集。比如在机器翻译中,我们有源语言数据集 X 和目标语言数据集 Y。我们希望学习一个模型,能够把 X 中的句子翻译成 Y 中的句子。按照传统的思路,这是一个条件概率问题:给定 X,Y 的概率分布是什么?用 K氏复杂度来表示,就是求 K(Y|X),即给定 X 的条件下,Y 的最短描述长度。
然而, Ilya 提出了一个不同的思路。他说,与其像监督学习那样将 X 和 Y 视为条件与结果,不如将它们视为一个整体,在一个巨大的模型里面一起进行压缩。也就是说,我们要寻找一个联合的 K氏复杂度 K(X,Y),即同时压缩 X 和 Y 的最短程序长度,这就是我们的无监督学习出来的预训练大模型(LLM)。
这个联合压缩程序必须能够充分利用 X 和 Y 之间的相关性,用 X 中的信息去自动对齐 Y,就像我们学习外语时,会自然利用母语的知识去理解和记忆外语单词一样。
Ilya 认为,这种联合压缩的思想,才是无监督学习的真正威力所在。因为现实世界的数据往往是相互关联的,存在大量的深层共同模式和规律。如果我们能够用无监督学习去发现和利用这些规律,就能极大地提高学习的效率和泛化能力。
这也是 GPT 等大型语言模型能够在各种任务上展现惊人性能的原因:它们通过海量数据的无监督预训练,学会了训练集的种种内在规律性,而这种规律性在相关的数据间月有通用性,可以对齐。
当然,在数学上,真正的 K氏复杂度是不可计算的。但 Ilya 认为,我们可以用深度神经网络(例如GPT)去近似这个过程。通过梯度下降等优化算法,神经网络可以在海量数据中寻找最优的压缩表示,虽然可能不是严格意义上的 K氏复杂度,但足以捕捉数据的本质特征及其对齐规律。
所以, Ilya 的理论可以看作是一个无监督学习的新范式,它将传统的独立建模(如英语模型、汉语模型;再如,语言模型、视觉模型,等等)提升到了大一统的关联建模的高度。在这个范式下,无监督学习的目标不再是单纯地压缩单一群体的数据,而是寻找数据之间的联系。
这种跨模式、跨模态的学习,才是通用人工智能的高级形态。
现在我们仔细看这最后一张slide,里面的X是数据集1,Y是数据集2,要点是榨干X“海绵中的每一滴水(信息或价值)” 可以帮助预测Y,这就是 Ilya 说的X与Y一起训练所能造成的效果:无监督的X学习居然帮助完成了从X到Y的转换任务(预测Y就是转换成Y)。
最关键的思想是:K(YIX) 变成了 K(X, Y)。
就是说, Ilya 把“ input X 条件下的 output Y” 这个放之四海而皆准的函数式AI任务,改成一个近似的求解问题,即,变成一个X与Y按照“原生态”放在一起联合训练:这实际上就是目前多模态大一统对于输入数据不做模态切割的训练方式,简写为 K(X, Y)。
这种近似变换,的确在“序列学习是AI任务的万能模拟器”的实践上看到了效果,但缺乏论证。 Ilya 试图在理论上加强论证,并强调了自己的惊喜发现:X 的自学习居然对于Y的有很强的预测作用。
无监督自学习的本来含义是:X 的自学习就是为了压缩X;Y 的自学习就是为了压缩Y。
这个容易理解,因为自学习的本质就是回归,只有正例(但可以有理论上无穷的正例),没有反例。无监督自学习没有具体的任务指向,是从语言学习语言,从图像学习图像,从音乐学习音乐,等等,实质就是从现象中不断归纳和抽象大大小小的规律性(各种 patterns)。
Ilya 在 slide 里面指出:Conditioning on a dataset, not an example。
压缩的对象是数据集,而不是数据点,这一点非常重要,这其实是形式压缩与内容压缩的分水岭。形式压缩只是一个机械过程,产生不了智能。只有内容压缩才能成就人工智能。
如何理解形式的无损压缩(例如数字音乐)与内容的无损压缩(例如 Suno)的区分和联系?
对一首特定的歌曲做无损压缩,目的是要保证压缩后可以100%还原成原来的音乐形式(包括音乐中的噪音和瑕疵)。这是传统意义上的音乐压缩,对象是数据个体,即,那首音乐。如果我们对音乐的集合做压缩,无论大模型是用GPT还是用 Diffusion,你的对象就不再是个体,而是一个群体,结果就是大模型了,例如Suno。
但个体对象转变为群体对象的时候,形式的压缩就自然转化为内容的压缩。这是因为群体虽然是个体组成的,但为群体压缩,如同是为群体“画像”,勾勒的是群体的统计性形象,它看上去可能是个个体,但它不是原数据中的任何一个特定的个体复制,否则就不是模型,而是记忆库了。
这不难理解,因为大模型压缩的本意就是要找出数据集的特征和规律性。
你看,大模型GPT4生成的文字,我们可能似曾相读;大模型 Suno 生成的音乐,我们可能似曾相闻;大模型 Sora 生成的视频,我们可能似曾相见;大模型 MJ 生成的图片,我们可能似曾相识。
但它们是在大数据作为整体被抽象或压缩以后,根据 prompt trigger 的条件,重新“还原”出来的虚拟个体:源于数据,高于数据,混迹于数据,真假莫辨。
既然压缩的对象是整个的 dataset 的内容,解压以后如何衡量其效果呢?黄金标准在哪里?新人可能没意识到,无监督也要有标准的。实践层面,黄金标准是有的,否则没法训练。
这个标准就是每一个sample自己,等于是回到了个体。但这是不确切不完整的,标准完全有可能是其他的等价答案,因为同一个内容是可以有多种说法或形式表达的。
所谓自学习,就是以逼近个体为手段,不断逼近群体。实现手段就是所谓“掩码”(把自己披上个红盖头),ntp 就把 next token 遮盖住。训练就是计算与每一个sample的loss,利用梯度下降的 back prop不断调参,最后让这个 loss 在数据集群体训练中下降到一个可以接受的点,大模型就炼成了。
最后这张slide和 Ilya 的解释,都在强调一个核心观点:条件 K氏复杂度 K(Y|X) 提供了一种理论上最优的无监督学习解决方案。
K(Y|X) 的定义: 在允许访问输入数据集 X 的情况下,输出数据集 Y 的最短程序的长度。
K(Y|X) 的意义: 它代表了从 X 中提取所有对预测 Y 有价值的信息的理论上限。一个能够达到 K(Y|X) 的算法,就是利用无标签数据 X 进行对于Y预测的最佳算法。
这实际上可以看成是大模型能做各种语言机器翻译的理论基础。因为每一种语言都是潜在的 X 也是潜在的 Y,在难以思议的语言数据量灌进去自学习以后,LLM 就学会了各种语言以及语言之间的关联性,也就具备了X--》Y 的翻译潜能。
实践中,机器翻译的任务在初期与其他任务的学习一样,是通过少量的翻译样本(few shots),在指令遵循的微调中定义了任务,最终触发了大模型对各种语言互译的内力。这种无监督学习各种任务的内力所依据的理论基础正是本次演讲的主题。
然而,K(Y|X) 在实际中是不可计算的。 Ilya 提出了一种可行的替代方案,即,使用普通的 K氏复杂度 K(X,Y)(联合压缩 X 和 Y)。他认为,在实际机器学习任务中,K(X,Y) 可以达到与 K(Y|X) 相当的效果。
重点的理论说十遍,上面这句话是精华的精华:条件建模被Ilya换成了序列建模,从而论证了 GPT 的大一统。以前在传统机器学习里面,最广为人知的一个概率近似变换是马尔科夫链式简化,与此有异曲同工的感觉。
结语
Ilya 在伯克利的历史性讲演,关于无监督学习的理论阐释,揭示的是自学习大模型,尤其是 GPT 几乎一统天下的奥秘。
Ilya 似乎思考和犹疑了很久,终于在伯克利隐晦泄漏了“天机”。虽然理论及其论证显得有些艰涩,但要真正搞懂GPT“预测下一词”的序列学习方式为什么成为 AI 任务的万能模拟器,这个讲演是一个必要的重要指引。
深究 Ilya 的演讲,将他的说法反复咀嚼,震撼之余,陡增了对他的钦仰。他以一种天才先知的形象,挟着他孤独求败与高处不胜寒,有一种大彻大悟、悲天悯人的气息,同时保持了一个实验室研究生nerd般的单纯、专注以及满怀理想的赤诚可爱。
他声称自己偏好压缩,但并不强调所谓无损压缩。他给自己,也给主流留了余地,提出了“无遗憾”的说法——虽然 GPT 可能做不到无损或完美,但是他在理论上论证了没有更好的办法了,GPT 是最接近无损的无遗憾的模型。
当 Ilya 正式出山,建立“安全超级智能” SSI 公司,强调只有一个重点、一个目标、一个产品,那就是要用技术确保大模型将要带来的超级人工智能对人类是安全的。
“AI 将万世不朽,它的诞生如同开天辟地”。当Ilya 目光炯炯地谈及 AI 的进程,他也最有资格断言,并引领着,“迈向AGI的激动人心又危险的旅程”。
参考:返回搜狐,查看更多
- https://www.youtube.com/live/AKMuA_TVz3A?si=7dVfcBUv3rHBHtyT
- https://situational-awareness.ai/
责任编辑:

麦咏楠:
1秒前:问题在于,从数学上可以证明,K氏复杂度是不可计算的,也就是说不存在一个算法能够对任意输入X算出最短程序P。
戈春艳:
5秒前:在这个范式下,无监督学习的目标不再是单纯地压缩单一群体的数据,而是寻找数据之间的联系。
艾可:
9秒前:所以,图片不能太随机,数据集不能都是涂鸦,得有一定的规律性,无监督学习才能抓住它们的隐藏共性。
柳真颜:
4秒前:当然,题海再大,如果只是死记硬背,不去归纳总结,你的脑容量再大、“记忆力”再强,也只是一个填鸭式的学霸,缺乏真正的学习应变的能力(叫做“泛化”能力)。